Blog
- Home
- Entity Framework Core
- Entity Framework Core: small tips and tricks
Entity Framework Core: small tips and tricks
Entity Framework Core is an awesome way to abstract the database away. It provides a strongly typed object framework (ORM) so you can manipulate objects instead of queries and datatables to map yourself. It's a great tool in the .NET ecosystem because developers are often bad at writing SQL queries. Most of the developers can easily handle basic situations but when it comes to complicated queries or high-load ones, their skills reach out their limits and it can occurs big issues. By abstracting the database to make it something "codeable", EF Core makes the data querying easier but it's not a magic tool so some bad uses of it can still occurs some bad situations you prefer to avoid. This is some little tips & ticks that can easily avoid some pretty bads situations or make the debugging of them a little less painful.
TagWith
The TagWith method adds comments to the generated SQL query. You can use it to make the debugging easier when you try to understand some massive generated SQL queries which come from several linq queries. By adding comments to the SQL, you can identify the pieces of code you want to analyze, or make the difference between several pieces of code that generate pretty similar queries.
To use it, you have just to call the method and passing in parameter the comment you want to write in the generated SQL query:
var products = await _dbContext
.Products
.Where(x => x.CategoryId == 1)
.TagWith("Get all products from category 1")
.ToListAsync(cancellationToken);
This code will produces this SQL:
-- Get all products from category 1
SELECT * FROM [Products] WHERE [CategoryId] = 1;
Chunk
Databases are usualy slow at doing bulk updates. It's a good practice to split bulk processes into smaller manageable chunks, it makes the performances better and avoids other database user to experience significant blocking issues.
This operation is doeable by yourself but it's good to know that linq provides a clean and easy way to do it:
var customers = _dbContext.Customers;
foreach(var customersChunk in customers.Chunk(10))
{
// Do something here
}
In this example EF core will process the items 10 by 10.
Count > 0 instead of Any
Counting items and check if the result is greater than 0 is something I see a lot, even in production, and I never understood why. I think it's a bad habbit that comes from testing the Count property on .NET collections, like arrays, that is not bad because the result is already processed by .NET, but doing the same thing on the database querying is an horrible practice that can occurs massive lost of processing time. Why getting all the results, then count them in-memory by listing all the items instead of just checking if the database has one row?
public bool HasAnyProduct(int categoryId)
{
var products = _dbContext.Products
.Where(x=> x.CategoryId == categoryId)
.ToList();
return products.Count > 0;
}
Instead we can count items in the database directly which is way more efficient:
public bool HasAnyProduct(int categoryId)
{
return _dbContext.Products.Any(x=> x.CategoryId == categoryId);
}
AsNoTracking for readonly queries
When you get some entities, Entity Framework Core tracks every modification so it can apply the change in the database if you want. It's a very good feature because it makes the data manipulation very easy for the developer but it comes with a cost: the entities manipulated by Entity Framework are at least twice bigger than the ones you defined because EF Core adds a tracking field for each field of the entity.
But why keeping theses EF Core overloads when you know that you won't update the datas you are querying? You can apply the AsNoTracking EF Core extension method to ask EF Core do not apply his tradicional tracking. The gain is that EF Core will perform a lot faster and will use less memory, the trade-off is that any data modification change won't affect the database, so you have to keep in mind that you requested non-trackable datas.
Example of a non-trackable query:
public IEnumerable GetProducts(int categoryId)
{
return myDbContext.Products
.AsNoTracking()
.Where(x=>x.CategoryId == categoryId)
.ToList()
}
Post about this feature : Common EF Core mistake: not using the difference between Tracking and No-Tracking Queries
Avoid using update
The Update method of an entity set all his fields as updated so the whole object will be updated in the database, it results a longer operation that can cause locking issues.
Product product = await _context.Products.Single(x => x.Id == productId);
product.DiscountAmount = 50;
_context.Products.Update(product);
context.SaveChanges();
A lighter version of this code would be to update only the modified field and not the whole record.
Product product = await _context.Products.Single(x => x.Id == productId);
product.DiscountAmount = 50;
context.SaveChanges();
Using IEnumerable over IQueryable
IEnumerable and IQueryable are both usefull but works completely differently and it's very important to understand the difference. Iqueryable is EF Core LiNQ, which means that the queries runs out-of-memory. IEnumerable is standard LINQ so it runs in-memory.
To understand the difference, let's take the count example. Here some standard LINQ implementations (they may seems different bu they work exactly the same under the hood):
public int CountCustomers()
{
return _dbContext.Customers.ToList().Count;
}
public int CountCustomers()
{
IEnumerable customers = _dbContext.Customers;
return customers.Count();
}
public int CountCustomers()
{
return GetAllCustomers().Count();
}
public IEnumerable GetAllCustomers()
{
return _dbContext.Customers;
}
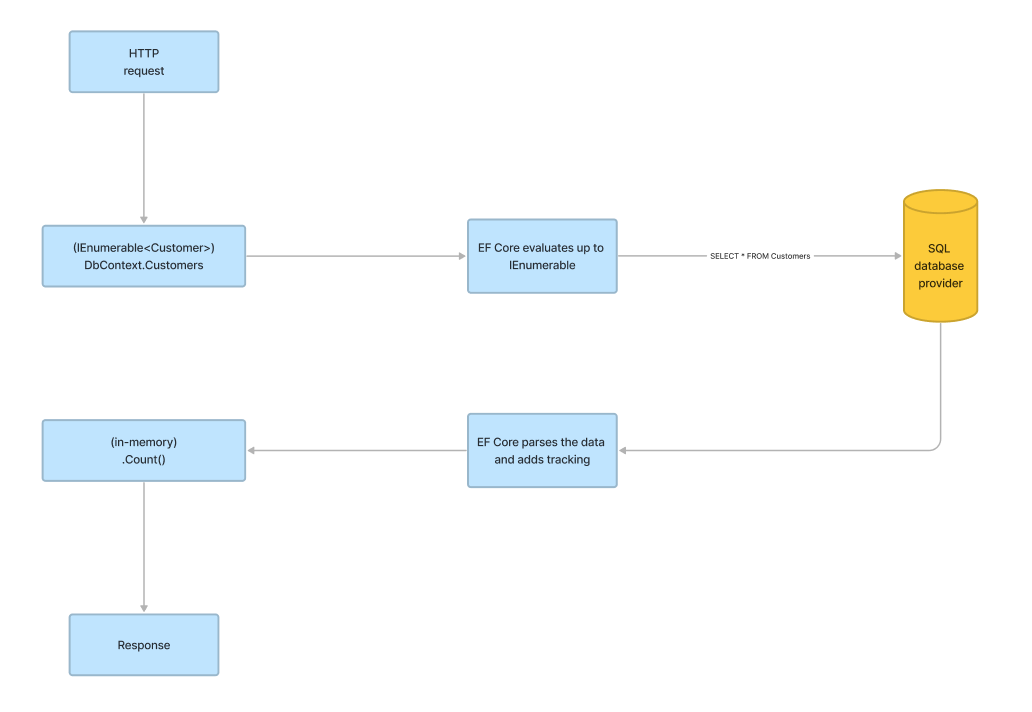
Yes, as you see the SQL query that is sends to the SQL database provider queries all the data (all the columns for all the rows), returns it to EF Core that needs to manage all these datas, adds his tracking then return the results on which a count is executed. It depends of your database but theses queries can returns millions of records... for a count...
SELECT * FROM [Customers] AS [C]
It leads us to the IQueryable
public int CountCustomers()
{
return _dbContext.Customers.Count();
}
public int CountCustomers()
{
return GetAllCustomers().Count();
}
public IQueryable GetAllCustomers()
{
return _dbContext.Customers;
}
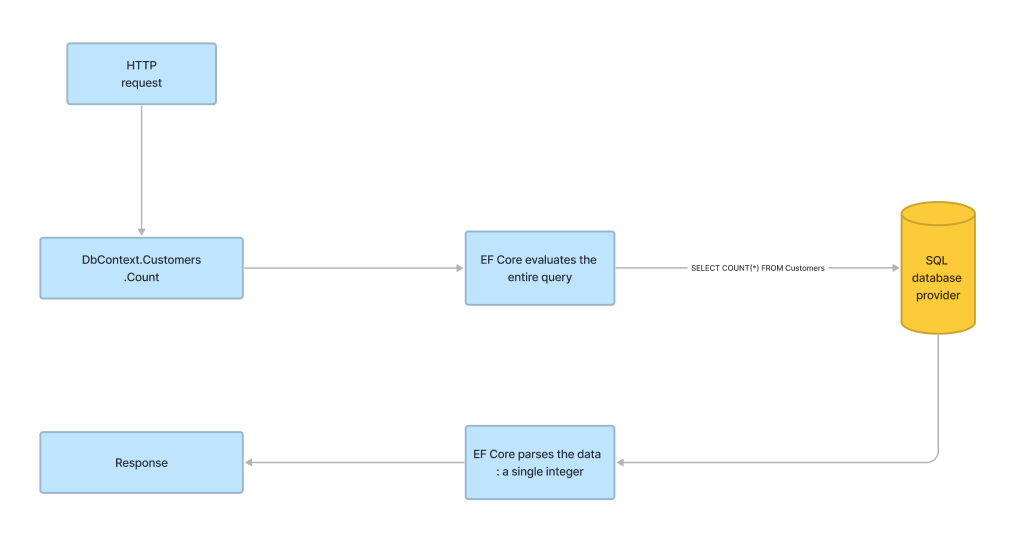
Notice that IQueryable